- unwind ai
- Posts
- Anthropic Accidentally Leaked Claude Code's Entire Source
Anthropic Accidentally Leaked Claude Code's Entire Source
+ Cohere drops the best open speech model
Shubham Saboo & Gargi Gupta
April 01, 2026
Today’s top AI Highlights:
& so much more!
Read time: 3 mins
AI Tutorial
Six AI agents run my entire life while I sleep.
Not a demo. Not a weekend project.
A real team that works 24/7, making sure I'm never behind. Research done. Content drafted. Code reviewed. Newsletter ready. By the time I open Telegram in the morning, they've already put in a full shift.
By the end of this, you will understand exactly how to build an autonomous AI agent team that runs while you sleep.

We share hands-on tutorials like this every week, designed to help you stay ahead in the world of AI. If you're serious about leveling up your AI skills and staying ahead of the curve, subscribe now and be the first to access our latest tutorials.
Latest Developments
Anthropic built an entire subsystem inside Claude Code called "Undercover Mode" to prevent the AI from accidentally leaking internal secrets.
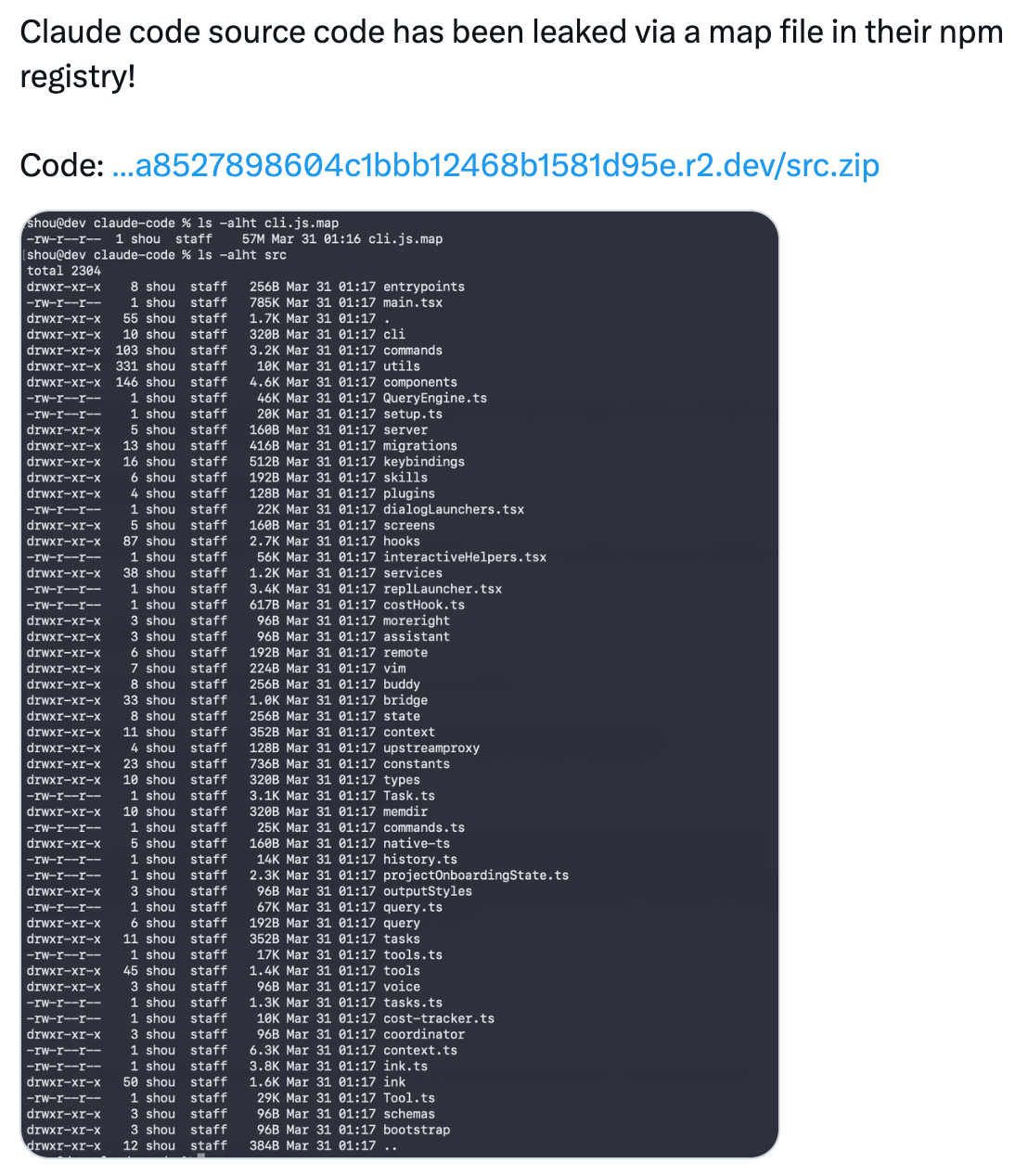
And then the entire source code, 512,000 lines of it, got leaked in a .map file they forgot to exclude from npm.
A security researcher spotted the 59.8 MB source map bundled into version 2.1.88 of the @anthropic-ai/claude-code package earlier today, and within hours the full unobfuscated TypeScript codebase was mirrored across GitHub, racking up tens of thousands of stars.
For builders, this is the Rosetta Stone of coding agents. The patterns Anthropic uses for tool orchestration, error recovery, and user experience management are production-tested at massive scale. You can study how they handle tool failures, manage context windows, and architect a plugin system. There are now many deep analyses that break down the architecture layer by layer.
Key Highlights:
Fake tool interception: Instead of blocking dangerous tool calls, Claude Code redirects them through dummy endpoints that return safe responses. A pattern you can replicate in your own agent systems.
Frustration-aware UX: Regex-based sentiment detection adjusts the agent's verbosity and approach when users show signs of annoyance. Solves the "agent keeps doing the wrong thing" loop.
Undercover mode: Hidden reasoning chains that run without surfacing to the user. Useful for agents that need to self-correct without cluttering the interface.
KAIROS: Persistent Background Agent: The headline feature buried in the code is an unreleased autonomous daemon mode with background memory consolidation ("autoDream"), daily append-only logs, and cron-scheduled refresh every 5 minutes. This is the scaffolding for Claude Code to work while you're away from your terminal.
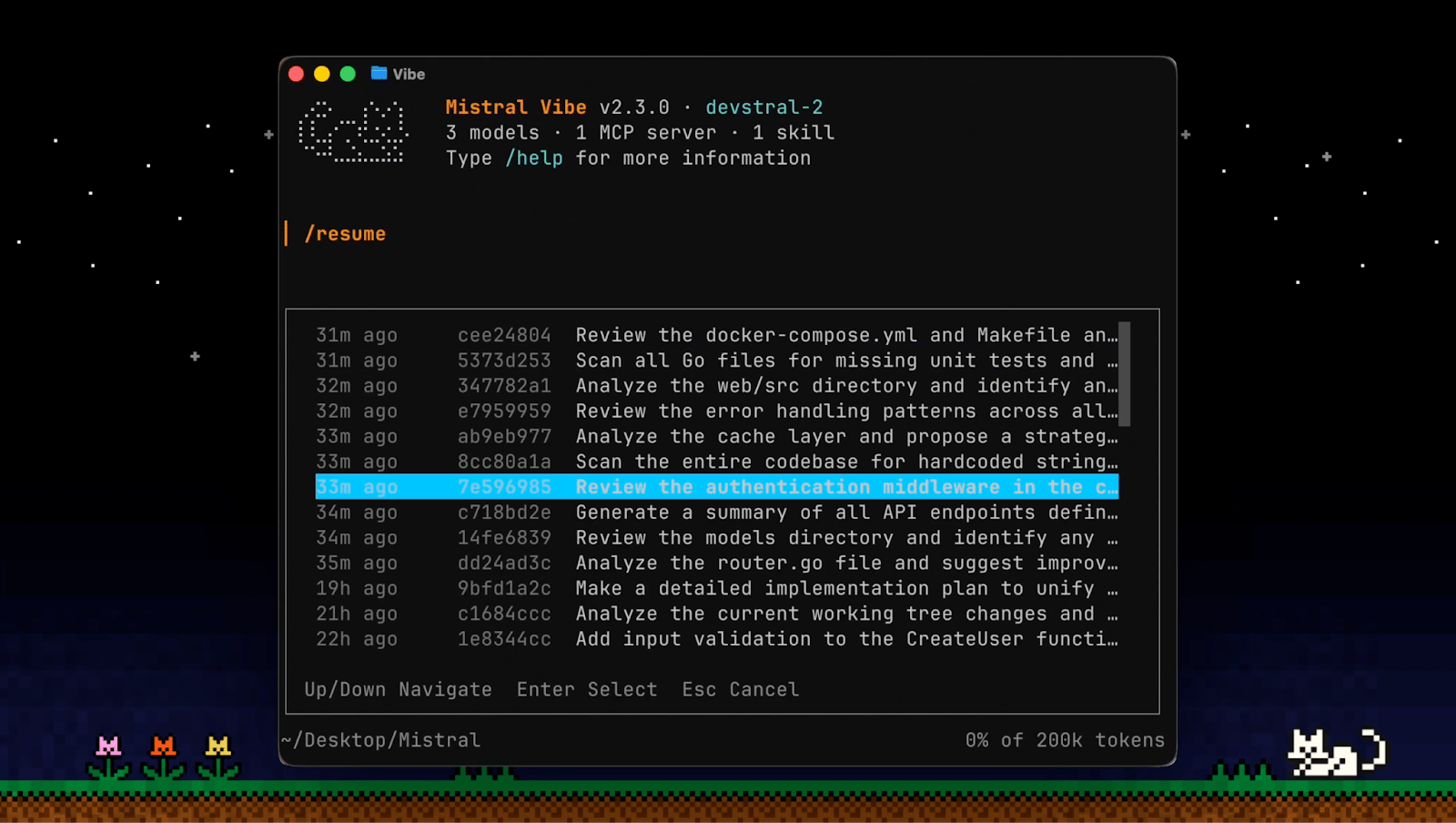
Vibe's CLI is built around autonomous execution: you describe a task, and the agent works through it across your codebase using its built-in toolset, directly from the terminal.
Here's what's new and worth knowing.
Web search mid-session - Vibe can now query and fetch content from the web without leaving your session. Useful for pulling in docs, checking APIs, or researching unfamiliar libraries while you work.
Ping notifications - Vibe lets you know when it needs attention: approvals, clarifications, or task completion. Kick off a long-running task and step away. It'll surface when it matters.
Session resume with /resume - Pick up any previous session with full context intact. No re-explaining, no lost state. Also available as vibe --continue in the terminal to resume your last session directly.
Multi-choice clarifications - When intent is ambiguous, Vibe prompts with structured options instead of guessing. Keeps long-running tasks on track without constant supervision.
/compact for long sessions - One command to keep the agent sharp across extended sessions by managing context efficiently.

Ollama just shipped a native Apple MLX backend. The numbers: 1,851 tokens per second prefill and 134 tok/s decode on an M5 chip.
That's fast enough to run a 35B model as your local coding agent with no cloud dependency and no API bills.
The technical unlock is NVFP4 quantization paired with MLX's metal-optimized compute path. Apple Silicon's unified memory architecture means large models stay in RAM without the GPU-to-CPU shuffle that slows down CUDA-based inference on consumer hardware.
A single terminal command gets you there: brew install ollama && ollama run qwen3.5:35b.
Why does this matter? Running a 35B model for code generation, RAG queries, or agent orchestration on a laptop was possible before, but painfully slow. At 134 tok/s decode, the experience feels native. Pair this with yesterday's Claude Code leak, and you have the ingredients for a fully local coding agent stack 💀
Key Highlights:
1,851 tok/s prefill: Context ingestion fast enough for large codebases. Feed it your entire project and get responses without waiting.
NVFP4 quantization: Aggressive compression that preserves quality on Apple Silicon. Run models that would normally need 64GB in 32GB.
One-liner setup:
ollama run qwen3.5:35b. No environment config, no dependency management, no Docker containers.Zero cloud cost: Every inference runs on your hardware. Build and test agents without watching your API dashboard.
Quick Bites
OpenAI just raised $122B (what the blog post won't cover!)
OpenAI just raised $122B at an $852B valuation, the largest private fundraise ever, with SoftBank, a16z, Sequoia, and BlackRock all in. That's roughly 5 years of current revenue raised in a single round from investors who can't afford to be the ones who sat it out. It leans heavily on flywheel diagrams and "AI superapp" framing, but one buried line about an ads pilot hitting $100M ARR in six weeks tells a different story. We unpacked all of it in this blog.
Google launches Veo 3.1 Lite: video generation at half the cost
Google Veo 3.1 Lite launched today. Text-to-video and image-to-video at less than half the cost of Veo 3.1 Fast. Available now through the Gemini API and Google AI Studio. If you're building video features into products, this is the cheapest high-quality generation API available.
Cohere drops #1 open ASR model that beats Whisper
Cohere Transcribe is the new #1 on HuggingFace's Open ASR Leaderboard. A 2B Conformer model hitting 5.42% word error rate across 14 languages, Apache 2.0 licensed. Beats Whisper Large v3 and ElevenLabs Scribe v2. Self-host your speech recognition with no vendor lock-in: pip install cohere-transcribe.
Axios npm package compromised with a remote access trojan
🚨 Axios npm supply chain attack: Version 1.14.1 on npm drops a remote access trojan via [email protected]. If you're building anything with JavaScript or TypeScript, check your lockfiles now. Thankfully, it hit #1 on Hacker News!
Tools of the Trade
Universal CLAUDE.md: A drop-in CLAUDE.md file you place in your project root that instructs Claude Code to cut the filler, banning fluff like "Great question!" openers, redundant closings, and scope creep. Can reduce output tokens by ~63%. The override rule lets you still ask for verbose output when you actually want it.
SentrySearch: Semantic search over video footage. Type what you're looking for, get a trimmed clip back. Built using Gemini Embedding 2 or Qwen3-VL and Chroma db. When you search, your text query is embedded into the same vector space and matched against the stored video embeddings. The top match is automatically trimmed from the original file and saved as a clip.
AIO Sandbox: An all-in-one agent sandbox environment that combines Browser, Shell, File, MCP operations, and VSCode Server in a single Docker container. Built on cloud-native lightweight sandbox technology, it provides a unified, secure execution environment for AI agents and developers.
Awesome LLM Apps - A curated collection of LLM apps with RAG, AI Agents, multi-agent teams, MCP, voice agents, and more. The apps use models from OpenAI, Anthropic, Google, and open-source models like DeepSeek, Qwen, and Llama that you can run locally on your computer.
(Now accepting GitHub sponsorships)

Hot Takes
Supply chain attacks like the currently breaking axios, litellm and xz are only going to be more commonplace in the vibecoding world.
The entire premise of vibecoding is “I don’t need to understand the code” happens to also be the entire premise of a supply chain attack.
~ Deedy
it is a little funny now how dario was on dwarkesh a month or two ago saying “other companies” were being irresponsible for buying so much compute
~ roon
That’s all for today! See you tomorrow with more such AI-filled content.
Don’t forget to share this newsletter on your social channels and tag Unwind AI to support us!
PS: We curate this AI newsletter every day for FREE, your support is what keeps us going. If you find value in what you read, share it with at least one, two (or 20) of your friends 😉
Reply