- unwind ai
- Posts
- Claude Opus 4.6 and GPT-5.3-Codex 30 Mins Apart
Claude Opus 4.6 and GPT-5.3-Codex 30 Mins Apart
+ OpenAI Frontier for building and managing enterprise AI agents
Shubham Saboo & Gargi Gupta
February 06, 2026
Today’s top AI Highlights:
& so much more!
Read time: 3 mins
AI Tutorial
Evaluating startup investments requires hours of research across multiple domains - company analysis, market research, financial modeling, and risk assessment. This setup literally automates this entire workflow with AI agents that work together like a real investment team.
In this tutorial, you'll build an AI Due Diligence Agent Team using Google's Agent Development Kit (ADK) and Gemini 3 models, and Nano Banana.
This 7-agent team researches any startup (from early-stage unknowns to well-funded companies), analyzes the market, builds financial projections, assesses risks, and generates professional investment reports - all autonomously with seamless handoffs and a sophisticated analysis with reports.

We share hands-on tutorials like this every week, designed to help you stay ahead in the world of AI. If you're serious about leveling up your AI skills and staying ahead of the curve, subscribe now and be the first to access our latest tutorials.
Latest Developments

Claude Opus 4.6 is here, and it's the first Opus-class model with a 1M token context window in beta, plus the ability to spin up multiple agents that coordinate autonomously.
Anthropic's newest flagship model isn't just smarter; it's built to handle the kind of sustained, complex work that used to require constant hand-holding.
The model plans more carefully, navigates massive codebases with better judgment, and catches its own mistakes through improved code review and debugging. On Terminal-Bench 2.0 (agentic coding), it tops every other model.
Opus 4.6 is much better at retrieving relevant information from large sets of documents, where it can hold and track information over hundreds of thousands of tokens with less drift, and picks up buried details that even Opus 4.5 would miss.
(☠️ RAG)
Key Highlights:
Agent Teams (Preview) — In Claude Code, you can now spawn multiple agents that work in parallel and coordinate autonomously, ideal for tasks like large codebase reviews that split into independent, read-heavy work.
Context Compaction — New API feature automatically summarizes older context when conversations approach limits, letting agents run longer without hitting the wall.
Adaptive Thinking + Effort Controls — Claude now decides when deeper reasoning helps, and developers get four effort levels (low, medium, high, max) to balance intelligence, speed, and cost.
Office Tool Integrations — Claude in Excel now handles multi-step changes in one pass and infers structure from unstructured data; Claude in PowerPoint (research preview) generates on-brand decks by reading your layouts, fonts, and slide masters.
Available now on claude.ai, API, and all major cloud platforms. If you’re a developer, use claude-opus-4-6 via the Claude API. Pricing remains the same at $5/$25 per million tokens.
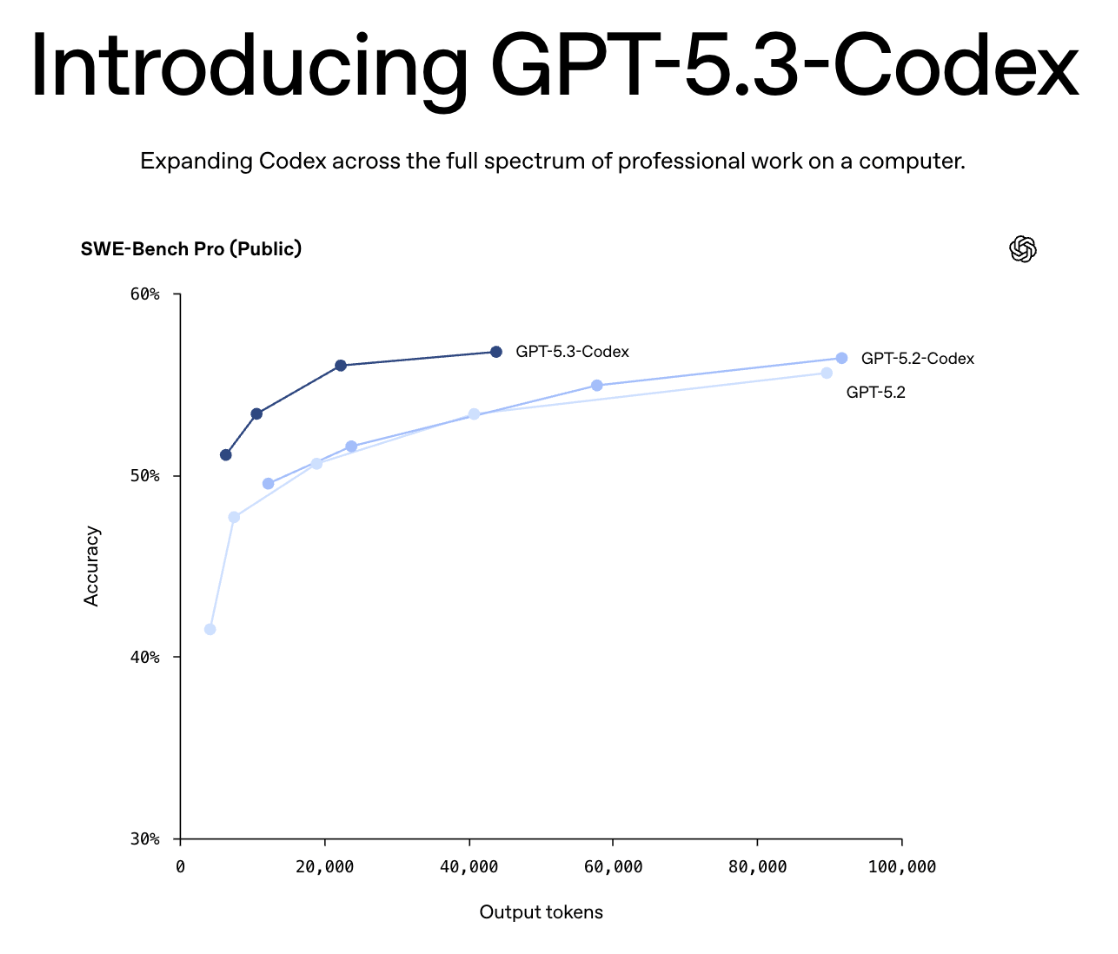
OpenAI dropped GPT-5.3-Codex literally 27 minutes apart. This wasn't a coincidence. This was a statement.
OpenAI's latest coding model, GPT-5.3-Codex, is the first model where early versions were actively used to debug its own training, manage deployment, and diagnose evaluation results during development.
The model merges the coding chops of GPT-5.2-Codex with the reasoning and knowledge capabilities of GPT-5.2 into a single, 25% faster package. It sets new highs on SWE-Bench Pro (56.8%), Terminal-Bench 2.0 (77.3%), and OSWorld-Verified (64.7%) — the last one putting it close to human-level performance on computer-use tasks (~72% human baseline).
You can steer it mid-task without losing context, making it feel more like pair programming than prompt-and-pray. GPT-5.3-Codex is available now for paid ChatGPT users across the Codex app, CLI, IDE extensions, and web, with API access coming soon.
Key Highlights:
Token Efficiency — Achieves state-of-the-art SWE-Bench Pro scores while using fewer output tokens than any prior model, meaning lower latency and potentially reduced cost per task for developers.
Interactive Steering — You can ask questions, discuss approaches, and redirect the model while it's working on long-running tasks — it provides frequent progress updates instead of just delivering a final output.
Full Lifecycle Coverage — Goes beyond code generation to handle debugging, deployment, monitoring, PRD writing, data analysis, and even building slide decks and spreadsheets.

Anthropic just open-sourced a fully functional C compiler. The twist: 16 Claude agents, powered by Opus 4.6, built it themselves. 100,000 lines of Rust. $20,000 in API costs. Two weeks of work.
The compiler passes 99% of GCC torture tests and can compile the Linux kernel. The human role shifted entirely from writing code to engineering the environment where agents could succeed.
Key Highlights:
100K Lines of Rust - Not a toy project. Production-grade compiler built entirely by AI agents working in coordination.
$20K Total Cost - Two weeks and twenty thousand dollars. That's the new cost to build serious infrastructure with agent teams.
Compiles Linux Kernel - The ultimate stress test. If it can handle the kernel, it can handle your codebase.
Open Source Now - Full code available on GitHub. Study how they structured agent coordination for complex tasks.
Check it out at github.com/anthropics/claudes-c-compiler
Quick Bites
OpenAI Frontier for building and deploying enterprise AI agents
OpenAI launched Frontier, an enterprise platform for building, deploying, and managing AI agents that can actually do work across an organization. The platform connects to existing data warehouses, CRMs, ticketing tools, and internal apps — giving agents shared business context without forcing companies to replatform. It's available today to a limited set of customers, with broader access rolling out over the next few months.
Mitchell Hashimoto's AI Adoption Journey
The HashiCorp founder shared his 6-step journey from AI skeptic to "no way I can go back." Key insight: stop using chatbots, start using agents. His rule now is to always have an agent running, kick off 30-minute tasks before ending the day, and engineer the harness so agents never make the same mistake twice.
DeepEval: Agent Trajectory Testing
Stop testing just outputs. DeepEval lets you test the entire agent decision tree: Did it pick the right tool? Valid parameters? Following its own reasoning? Actually achieved the goal? 13K+ GitHub stars, Apache 2.0 licensed.
BalatroBench: LLMs Playing Cards on Twitch
Want to benchmark your LLM in a fun way? BalatroBench makes models play Balatro autonomously. Opus 4.6 is currently playing live on Twitch. Write custom strategies with Jinja2 templates and compare performance across models on the leaderboard.
ClawHub Malware Alert
1Password's security team found malware hiding in a popular agent skill on ClawHub. If you're pulling skills from community repos, audit before you trust. A good reminder that agent tool ecosystems need the same security hygiene as npm or PyPI.
Tools of the Trade
OpenClaw on Emergent - Deploy OpenClaw from your browser in 2 minutes instead of 2 hours. No Mac mini, no terminal, no API key exposure. Everything sandboxed.
Fluid.sh - A terminal agent that creates sandbox clones of your production infrastructure, allowing AI to safely explore and test commands away from live systems. It uses these verified interactions to automatically generate Infrastructure-as-Code, such as Ansible playbooks, ready for deployment.
Mantic - A context-aware code search engine that prioritizes relevance over raw speed. After testing across 5 repositories (cal.com, next.js, tensorflow, supabase, chromium), it gives better results compared to grep/ripgrep, despite some trade-offs in speed for very large codebases.
Awesome LLM Apps - A curated collection of LLM apps with RAG, AI Agents, multi-agent teams, MCP, voice agents, and more. The apps use models from OpenAI, Anthropic, Google, and open-source models like DeepSeek, Qwen, and Llama that you can run locally on your computer.
(Now accepting GitHub sponsorships)

Hot Takes
The fastest way to validate a product:
DON'T build it
-Make a landing page
-Describe the problem it solves
-Add a "join waitlist" button
If nobody signs up, you just saved yourself 3 months
Vibe coding is here. Vibe research is next.
That’s all for today! See you tomorrow with more such AI-filled content.
Don’t forget to share this newsletter on your social channels and tag Unwind AI to support us!
PS: We curate this AI newsletter every day for FREE, your support is what keeps us going. If you find value in what you read, share it with at least one, two (or 20) of your friends 😉
1
Reply