- unwind ai
- Posts
- Code Execution with MCP by Anthropic
Code Execution with MCP by Anthropic
+ Microsoft teaches AI agents to wait, monitor, and act
Shubham Saboo & Gargi Gupta
November 06, 2025
In partnership with
Today’s top AI Highlights:
& so much more!
Read time: 3 mins
AI Tutorial
SEO optimization is both critical and time-consuming for teams building businesses. Manually auditing pages, researching competitors, and synthesizing actionable recommendations can eat up hours that you'd rather spend strategizing.
In this tutorial, we'll build an AI SEO Audit Team using Google's Agent Development Kit (ADK) and Gemini 2.5 Flash. This multi-agent system autonomously crawls any webpage, researches live search results, and delivers a polished optimization report through a clean web interface that traces every step of the workflow.
We share hands-on tutorials like this every week, designed to help you stay ahead in the world of AI. If you're serious about leveling up your AI skills and staying ahead of the curve, subscribe now and be the first to access our latest tutorials.

Latest Developments

Your AI agent can check emails, scrape prices, and book flights. But ask it to wait a few days for a colleague's response, and it'll crash. Not because it can’t do it, but because it doesn’t know when to check.
Currently, AI agents either give up after a few attempts or burn through tokens by obsessively checking every minute.
Microsoft Research released SentinelStep, a mechanism that teaches agents to wait, watch, and act at the right time. Built into their AI agent framework, Magentic UI, SentinelStep handles the two things agents consistently mess up: knowing when to check, and managing context over long durations.
It adjusts polling intervals based on what you're monitoring (like checking email vs tracking quarterly earnings). It saves the agent's state after the first check and reuses it for every subsequent check, preventing context overflow on tasks that run for days.
Testing shows success rates for 2-hour tasks jumping from 5.6% to 38.9%.
Key Highlights:
Polling Management - SentinelStep makes educated guesses about polling intervals based on task characteristics, then dynamically adjusts based on observed behavior to balance token efficiency with timely notifications.
No Context Overflow - The system saves agent state after the first check and reuses it for subsequent checks, allowing monitoring tasks to run for days without hitting context limits.
Three Components - Each monitoring step consists of actions to collect information, a condition determining task completion, and a polling interval for timing, exposed through Magentic-UI's co-planning interface for user review and adjustment.
Open Source - Available on GitHub as part of Magentic-UI, with documentation covering setup, use cases, and safety guidelines.
Attention spans are shrinking. Get proven tips on how to adapt:

Mobile attention is collapsing.
In 2018, mobile ads held attention for 3.4 seconds on average.
Today, it’s just 2.2 seconds.
That’s a 35% drop in only 7 years. And a massive challenge for marketers.
The State of Advertising 2025 shows what’s happening and how to adapt.
Get science-backed insights from a year of neuroscience research and top industry trends from 300+ marketing leaders. For free.
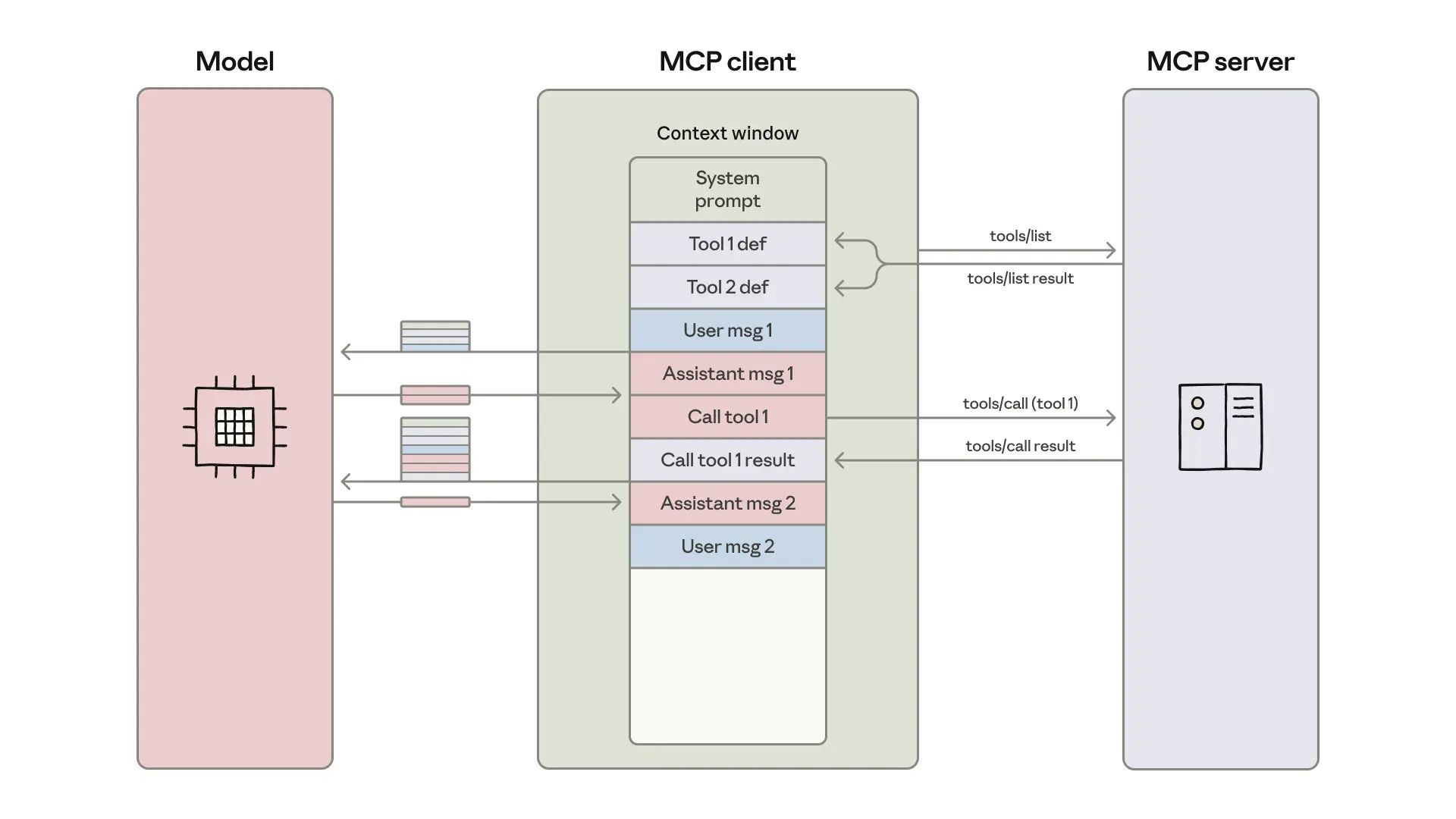
It’s a treat to read every blog post from the Anthropic Engineering team.
Token costs and latency are bottlenecking your MCP-powered agents. Every tool definition you expose gets loaded into context upfront, and every intermediate result has to round-trip through the model, even when the agent is just moving data from Point A to Point B.
The team published a pattern that sidesteps both issues: present your MCP servers as code APIs in a filesystem structure, give your agent a code execution environment, and let it write actual programs that interact with your tools. This method leverages what LLMs are naturally good at (writing code) to solve what they're naturally bad at (context window management).
This is pretty similar to what Cloudflare proposed in its blog “Code Mode.” We’ll discuss the differences later.
Key Highlights:
Progressive tool loading - Generate a file tree of your MCP servers, where each tool becomes a TypeScript file the agent can explore on-demand. Your agent lists the
./servers/directory, finds relevant servers, and reads only the specific tool definitions it needs for the current task instead of loading everything upfront.Data filtering in execution environments - Process large datasets directly in code before results hit the model. When fetching a 10,000-row spreadsheet, filter for the 50 pending orders you actually need and log only the first 5 for review. Your agent sees 5 rows instead of 10,000 bloating your context.
Control flow without token waste - Write loops, conditionals, and error handling as actual code patterns rather than chaining individual tool calls. A polling loop checking Slack for notifications runs entirely in the execution environment instead of alternating between MCP calls and sleep commands through your agent loop.
Privacy-preserving data flows - Intermediate results stay in the execution environment by default, and the agent only sees what you explicitly log or return. Implement automatic tokenization so sensitive data like email addresses and phone numbers flow from Google Sheets to Salesforce without ever entering the model's context.
Persistent skills and state management - Save working code as reusable functions in a
./skills/directory that agents can import later. Write intermediate results to files so agents can resume work, track progress, and build a growing toolbox of higher-level capabilities specific to your workflows.
Recommend reading the entire blog to dive deeper into each of these principles.
And here’s a comparison between Anthropic’s method and Cloudflare Code Mode:
Aspect | Cloudflare | Anthropic |
|---|---|---|
Core Concept | Convert MCP schemas into TypeScript APIs that agents write code against | Present MCP tools as code APIs in a filesystem structure for agents to interact with |
Tool Discovery | Loads all TypeScript type definitions into context upfront (with plans for dynamic browsing) | Filesystem-based progressive disclosure - agent lists directories and reads only needed tool files |
Context Efficiency | Type definitions loaded initially, but execution happens in a sandbox | Extreme token reduction (98.7%) by loading only required tool definitions on demand |
Best For | Teams wanting production infrastructure out of the box with Cloudflare's platform | Teams building custom agent architectures who need the efficiency pattern |
Quick Bites
Jules extension in Gemini CLI for background tasks
Google launched the Jules extension for Gemini CLI, letting you spin off coding tasks to an autonomous agent that works in the background. The workflow is straightforward: use /jules to delegate tasks like module conversions or refactoring, and Jules spins up a VM to clone your code and make changes while you keep working in your main CLI session.
Open voice AI model from India ranking #2 globally
Two 23-year-old Indian founders just dropped Maya1, a 3B open-source voice model that ranks #2 in open-weight voice AI models (as per Artificial Analysis leaderboard), can handle 20+ emotions with sub-100ms latency on a single GPU. You describe voices in natural language ("40-year-old, warm, low pitch") and add inline emotion tags directly in your text - no complex parameters or training data needed. Open-sourced under Apache 2.0 with full vLLM support.
1.1 Million tokens per second with Llama 2 70B on Azure VMs
Microsoft's new Azure ND GB300 v6 VMs just hit 1.1 million tokens per second running Llama2 70B inference - a 27% jump over their previous record with GB200 chips. Each Blackwell Ultra GPU pushes 15,200 tokens/sec, that’s nearly 5× faster than H100 instances at FP4 precision. The instances are now available on Azure for enterprise production inference workloads.
Deploy customer support AI agents at enterprise scale within 2 weeks
Giga AI just raised $61M Series A to automate customer operations for companies like DoorDash. What started as two college roommates fine-tuning LLMs pivoted hard into customer support after actually talking to customers, not out of passion, but pragmatism.
Their pitch is compelling: self-improving agents that jump from 60% to 98% resolution automatically, two-week deployment windows instead of months, and voice experiences in 99 languages with ultra-low latency. Here's what happens:
Upload your company’s documents, transcripts, policies, and even massive JSON files containing 1000s of internal workflows, and in seconds, an AI Agent is ready to reason, respond, and improve on your operational logic.
Giga AI gives a low-code environment where you can build, test, and launch your customized voice agents.
Their AI developer, Atlas, integrates with your system and helps you refine and extend what you’ve built. For example, creating APIs simply by pasting a link.
Deploy AI agents that handle voice and chat seamlessly, while maintaining a consistent brand voice and low latency.
You can analyze every conversation in real-time across millions of interactions to analyze how your agent is performing and get suggestions on how to further optimize.
If you're handling customer ops at scale, this is worth a closer look.
Quick Gemini app drops:
Gemini can now generate presentations with one click, complete with images and data viz, which you can then export to Google Slides for final tweaks. Upload your project notes or any source material, and Canvas in Gemini will build out the deck for you. Rolling out to Pro subscribers today, with free users getting access in the coming weeks.
Gemini Deep Research can now draw on context from your Gmail, Drive, and Chat and work it directly into your research. You can create even more comprehensive reports by pulling in information directly from your Gmail, Drive (including Docs, Slides, Sheets and PDFs) and Google Chat, alongside a variety of sources from the web. Available to all Gemini users.
Tools of the Trade
Agor - Run Claude Code, Codex, Gemini, and other CLI agents in one spatial canvas with managed git worktrees and persistent dev environments. It provides real-time team collaboration capabilities with cursors and comments, and session forking/subsessions for exploring alternative approaches.
Plexe - Build production-grade ML models from simple prompts. It automates data analysis, feature engineering, multi-architecture experimentation, and deployment. It uses multiple specialized agents that handle different pipeline stages, generating exportable Python code and comprehensive evaluations along the way.
FlowLens - A Chrome extension and MCP server that records browser sessions, capturing video, console logs, network requests, user actions, and storage state, and exposes it through an MCP server to AI agents like Claude Code.
Awesome LLM Apps - A curated collection of LLM apps with RAG, AI Agents, multi-agent teams, MCP, voice agents, and more. The apps use models from OpenAI, Anthropic, Google, and open-source models like DeepSeek, Qwen, and Llama that you can run locally on your computer.
(Now accepting GitHub sponsorships)

Hot Takes
blogpost I'm too lazy to write but you can extrapolate from the title:
Spec Driven Development is Wishful Thinking
~ swyx
ASI will happen
Because of tech? No
Because the average IQ will experience such a steep drop that exceeding human intelligence becomes trivial
That’s all for today! See you tomorrow with more such AI-filled content.
Don’t forget to share this newsletter on your social channels and tag Unwind AI to support us!
PS: We curate this AI newsletter every day for FREE, your support is what keeps us going. If you find value in what you read, share it with at least one, two (or 20) of your friends 😉
Reply