- unwind ai
- Posts
- Open Source Claude Cowork using Deep Agents
Open Source Claude Cowork using Deep Agents
+ Google’s open and local Gemma 3 models for on-device translation
Shubham Saboo & Gargi Gupta
January 19, 2026
In partnership with
Today’s top AI Highlights:
& so much more!
Read time: 3 mins
AI Tutorial
Evaluating startup investments requires hours of research across multiple domains - company analysis, market research, financial modeling, and risk assessment. This setup literally automates this entire workflow with AI agents that work together like a real investment team.
In this tutorial, you'll build an AI Due Diligence Agent Team using Google's Agent Development Kit (ADK) and Gemini 3 models, and Nano Banana.
This 7-agent team researches any startup (from early-stage unknowns to well-funded companies), analyzes the market, builds financial projections, assesses risks, and generates professional investment reports - all autonomously with seamless handoffs and a sophisticated analysis with reports.

We share hands-on tutorials like this every week, designed to help you stay ahead in the world of AI. If you're serious about leveling up your AI skills and staying ahead of the curve, subscribe now and be the first to access our latest tutorials.
Latest Developments
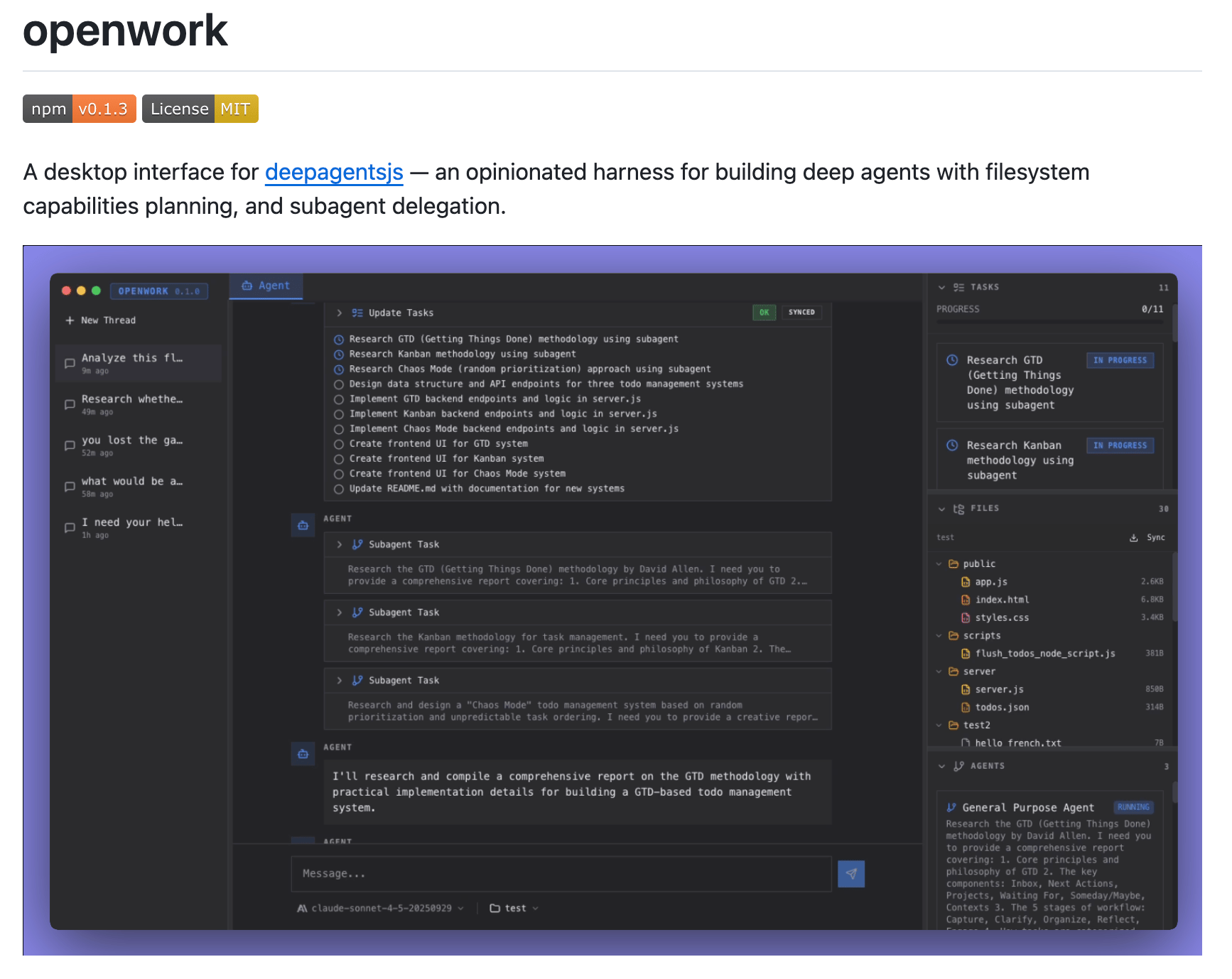
Claude Cowork just dropped, and LangChain didn't waste time.
Three days later, they shipped OpenWork, a fully open-source desktop agent built on their DeepAgents framework that brings the same file manipulation and autonomous execution capabilities to any developer's machine.
No subscriptions, no waitlists, just npx openwork and you're running a Claude Code-style agent locally with your choice of model.
OpenWork runs on the DeepAgents harness that LangChain released back in July 2025. DeepAgents was directly inspired by reverse-engineering what made Claude Code work - the planning tools, filesystem access, and subagent spawning that let agents handle complex, multi-step tasks without falling apart. Now that same architecture powers a desktop app that anyone can run, modify, or fork.
Key Highlights:
Multi-Model Support - Works with Claude 4.5 (Opus, Sonnet, Haiku), GPT-5 series, o-series reasoning models, and Gemini 3/2.5 family. Switch between providers without changing your workflow or rebuilding anything.
Full Filesystem Control - The LocalSandbox backend gives agents direct read/write access to your project folders with shell command execution. Commands run in isolated environments with configurable timeouts and output limits, plus human-in-the-loop approval for anything destructive.
Built-in Planning & Delegation - Agents automatically break down complex tasks into tracked todos, spawn specialized subagents for isolated work, and offload large context to files when approaching token limits. The middleware handles summarization, prompt caching, and context management without manual intervention.
Real-Time State Streaming - The agent runtime streams both token generation (for live response updates) and full state changes (todos, files, subagents) simultaneously. UI updates reflect planning decisions, file modifications, and tool executions as they happen.
Better prompts. Better AI output.

AI gets smarter when your input is complete. Wispr Flow helps you think out loud and capture full context by voice, then turns that speech into a clean, structured prompt you can paste into ChatGPT, Claude, or any assistant. No more chopping up thoughts into typed paragraphs. Preserve constraints, examples, edge cases, and tone by speaking them once. The result is faster iteration, more precise outputs, and less time re-prompting. Try Wispr Flow for AI or see a 30-second demo.

AI agents like Claude Code feel like black boxes wrapped in mystery. You type a vague request, and somehow they navigate your codebase, edit files, and write working code.
But strip away the polish, and you'll find something surprisingly simple: the entire architecture is just an LLM with three tools having a conversation with your filesystem.
Check out this implementation by Mihail Eric where he builds a functional coding agent in about 200 lines of Python.
The mental model is straightforward - you send a message, the LLM responds with structured tool calls, your code executes those calls locally, and the results flow back to continue the conversation. The LLM never directly touches your files; it just asks for things to happen through three core capabilities: reading files to see your code, listing files to navigate your project, and editing files to create or modify code.
Everything beyond this - error handling, streaming responses, approval workflows - is production polish, not architectural necessity.
Key Highlights:
Tool-based architecture - The agent operates through a simple loop where the LLM requests tool invocations in a structured format, your program executes them locally and returns results, and the LLM uses that context to continue or respond with more tool calls.
Dynamic tool discovery - Tools are registered in a simple dictionary and their capabilities are communicated to the LLM through automatically generated descriptions from function signatures and docstrings, letting the LLM figure out when and how to use them without hardcoded logic.
Multi-step execution - An inner loop allows the agent to chain multiple tool calls autonomously, like reading a file to understand its current state, then editing it, then confirming the change, without requiring user input between each step.
Minimal dependencies - The entire implementation uses only standard Python libraries plus an LLM API client, proving that the core pattern doesn't require specialized agent frameworks or complex orchestration systems to work effectively.
Read the full implementation and try it yourself.
Quick Bites
Firecrawl’s new models undercut Manus, Exa, and Parallel
Firecrawl just dropped Spark 1 Pro and Spark 1 Mini, two new models powering their /agent endpoint that handles web extraction from a single prompt. Mini runs 60% cheaper and handles standard tasks at 40% recall, while Pro leads the pack at 50% recall for complex research, both significantly cheaper than alternatives from Manus, Parallel, and Exa. You describe what data you need, the agent navigates and extracts it, and you choose between cost efficiency (Mini) or maximum accuracy (Pro).
Standard install.md file for agents to install software
Mintlify just launched install.md, a standardized format that lets AI agents autonomously install software by reading markdown instructions instead of executing mystery bash scripts. The idea is simple: host an install.md file with structured, human-readable steps that LLMs can parse and execute (with optional approval gates), adapting to whatever environment you're running. Mintlify auto-generates these for all their hosted docs sites, and the spec is open source if you want to add one to your own project.
Open-source SOTA TTS running 100% locally
The French AI voice darling, Kyutai, just released Pocket TTS, a 100M-parameter text-to-speech model that clones voices from 5 seconds of audio and runs faster than real-time on your CPU. No GPU needed. It's built on their new Continuous Audio Language Models framework, hits 1.84% word error rate (best in class), and ships open-source under MIT license with full training code and 88k hours of public training data.
BFL releases FLUX.2 [klein] for real-time image gen and editing
Black Forest Labs just dropped FLUX.2 [klein], their fastest image model yet, generating or editing images in under 0.5 seconds while running on consumer GPUs like the RTX 3090. The model unifies text-to-image, editing, and multi-reference generation in a single architecture. They're releasing it in 4B (Apache 2.0) and 9B versions with quantized FP8 and NVFP4 options that deliver up to 2.7x faster performance, basically bringing production-level visual generation to local GPUs.
Google’s open and local Gemma 3 models for on-device translation
Google just dropped TranslateGemma, a family of open translation models built on Gemma 3 that covers 55 languages. The efficiency gains are notable: their 12B model beats the 27B baseline while the 4B rivals the original 12B baseline, all thanks to distilling knowledge from Gemini models through specialized fine-tuning. Runs everywhere from mobile devices to a single H100, available now for download.
Tools of the Trade
Vibecraft - Turns your Claude Code instances into a 3D spatial interface where you can watch multiple AI agents work simultaneously across different zones. It's a visual control center that syncs with your local machine - complete with spatial audio so you actually hear which Claude is doing what.
figma-use - A CLI that lets AI agents design in Figma. It gives AI agents full read/write access to Figma through 100+ commands and JSX rendering that's 100x faster than plugin APIs. AI agents can write React-style components that compile directly into Figma frames, components, and auto-layouts.
Blackbox Agents API - One API that lets you run Claude Code, Codex, Gemini CLI, and other coding agents on remote VMs. The interesting bit is that you dispatch the same task to multiple agents simultaneously, then let a "chairman LLM" pick the best solution from all their attempts.
Humanizer - A Claude Code skill that strips 24 telltale patterns from AI-generated text, like "serves as a testament to" and "not just X but Y", based on Wikipedia's AI detection guide.
Awesome LLM Apps - A curated collection of LLM apps with RAG, AI Agents, multi-agent teams, MCP, voice agents, and more. The apps use models from OpenAI, Anthropic, Google, and open-source models like DeepSeek, Qwen, and Llama that you can run locally on your computer.
(Now accepting GitHub sponsorships)

Hot Takes
anthropic's $200 max plan is your last chance to escape the permanent underclass fyi when they shut it off one day that's it
Not everything is an agent. Not everything needs "agentic" capabilities.
In fact, 99% of the time, what you need is regular code.
If that doesn't work, you probably want to build a predefined workflow that combines large language models to solve the problem.
A hardcoded workflow is not an agent. It's just a workflow that uses an LLM.
If none of the above solves your problem, and only then, you should start thinking about an agent.
Right now, agents are probably one of the most complex solutions you'll have to implement. You never want to start there.
~ Santiago
That’s all for today! See you tomorrow with more such AI-filled content.
Don’t forget to share this newsletter on your social channels and tag Unwind AI to support us!
PS: We curate this AI newsletter every day for FREE, your support is what keeps us going. If you find value in what you read, share it with at least one, two (or 20) of your friends 😉
Reply