- unwind ai
- Posts
- Open Source Human-like Memory for AI Agents
Open Source Human-like Memory for AI Agents
+ Structured RAG to fix RAG blindspots, OpenAI GPT 5.1 is out
Shubham Saboo & Gargi Gupta
November 14, 2025
In partnership with
Today’s top AI Highlights:
& so much more!
Read time: 3 mins
AI Tutorial
Google's free 5-day AI Agents Intensive course ends today!
This course by Google's ML researchers covers everything from agent foundations to production-ready systems.
And they released 5 whitepapers (~300 pages total) that are staying up for free.
Here's what the whitepapers cover:
The 5 levels of agents: from pure reasoning to self-evolving systems
Core components: Model (the brain), Tools (the hands), Orchestration (the nervous system)
Moving from prototype to enterprise-grade systems
How tools actually work and why descriptions matter more than code
The Model Context Protocol architecture explained
Security risks nobody talks about: dynamic capability injection, tool shadowing, confused deputy problems
The difference between prompt engineering vs context engineering
Session management: conversation history + working memory
Memory as an active curation system, not just "save the conversation"
The four pillars: Effectiveness, Efficiency, Robustness, Safety
Process evaluation: judging reasoning, not just outputs
Building agents that learn from production failures
Evaluation gates, circuit breakers, and evolution loops
Turning demos into production systems
Real-time monitoring and continuous evaluation
The best part?
All whitepapers are 100% free and packed with zero fluff.

Latest Developments

Never repeat context to your AI agents again - just add memori.enable()
Memori is a memory engine that gives any LLM human-like, persistent, contextual memory. It uses your existing SQL databases with full ownership and zero vendor lock-in, cutting memory costs by 80-90% compared to vector databases.
The interesting part is how it works: Memori uses a team of multiple AI agents that run in the background and capture the conversation between your user and the LLM, process them to understand what's important (facts about the user, their preferences, project context), and automatically inject relevant memories into future chats.
The entire stack is open-source under Apache 2.0, with examples covering everything from basic personal assistants to multi-agent research platforms.
Key Highlights:
Three AI agents handle the memory - Memory Agent processes conversations with structured Pydantic models to extract entities and categorize information. Conscious Agent analyzes patterns to promote important memories. Retrieval Agent searches intelligently when you need dynamic context per query.
Pick your memory strategy - Use Conscious mode when you need fast responses with essential context (personal assistants, support bots). Use Auto mode when each query needs a different context (research agents, Q&A systems). Use Combined mode when you want both persistent preferences and dynamic knowledge retrieval.
LLM Agnostic - Native support through LiteLLM callbacks for OpenAI, Anthropic, Azure, Ollama, and any OpenAI-compatible endpoint. Works with popular frameworks like LangChain, AutoGen, and CrewAI without code changes.
Memory you can actually query - Run SQL against your conversation history, build analytics on user preferences, or export everything as SQLite to move wherever you want. Full-text search, entity relationships, and importance scoring are built into the schema.
Check out the repo, try the examples, and drop a star if you find it useful ⭐️
Become the go-to AI expert in 30 days

AI keeps coming up at work, but you still don't get it?
That's exactly why 1M+ professionals working at Google, Meta, and OpenAI read Superhuman AI daily.
Here's what you get:
Daily AI news that matters for your career - Filtered from 1000s of sources so you know what affects your industry.
Step-by-step tutorials you can use immediately - Real prompts and workflows that solve actual business problems.
New AI tools tested and reviewed - We try everything to deliver tools that drive real results.
All in just 3 minutes a day
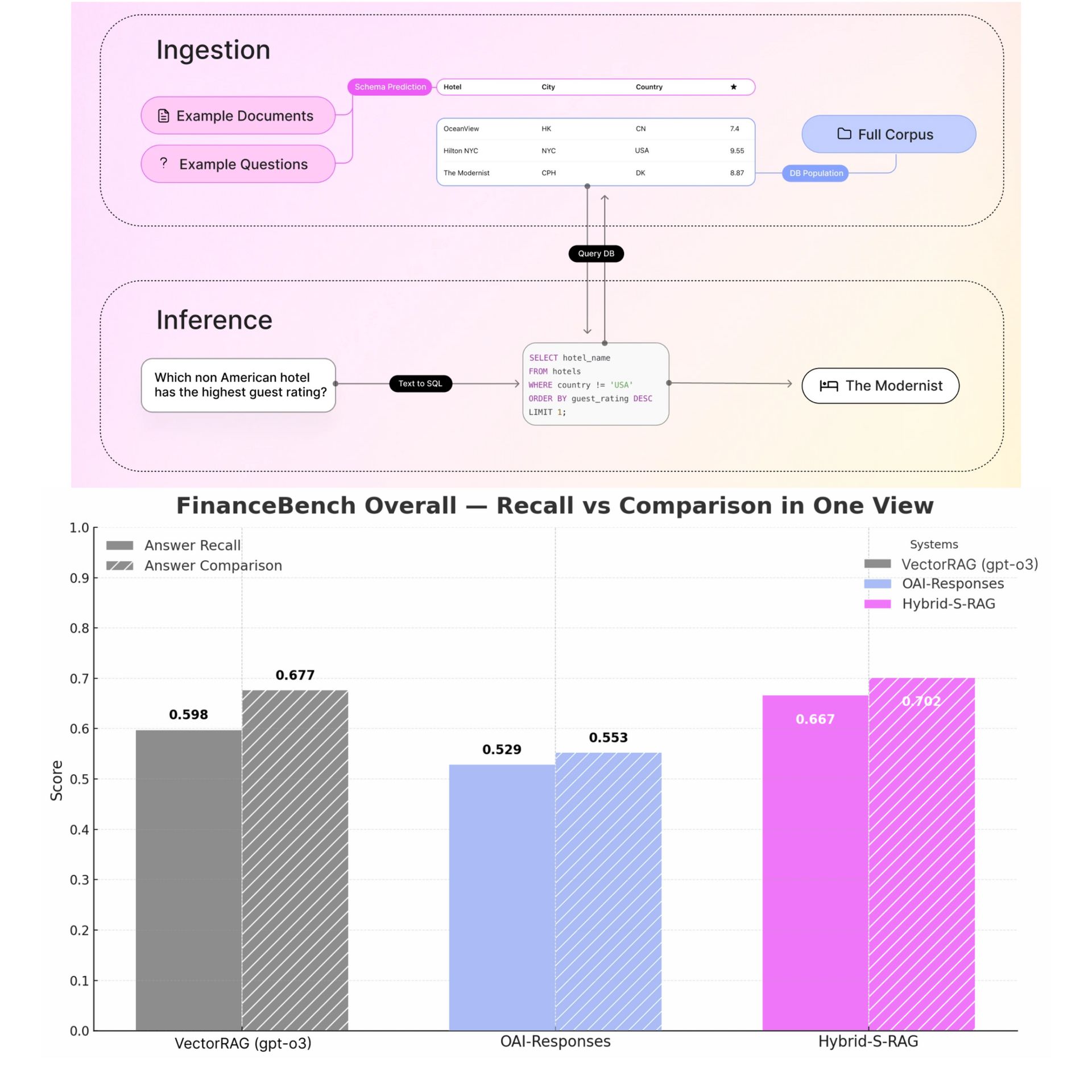
Ask a traditional RAG system, "who are the top five suppliers by on-time delivery rates?" and watch it struggle.
The retriever finds semantically similar passages, the LLM attempts arithmetic on a limited context, and you get an answer that might be plausible but definitely not reliable.
AI21 has released Structured RAG (S-RAG) in Maestro, their agentic RAG system. S-RAG is a hybrid system that converts unstructured documents into relational databases at ingestion time, then uses SQL to retrieve exact values.
It combines structured and embedding-based retrieval to handle both analytical queries requiring precise calculations and nuanced questions needing semantic understanding. It outperforms standard RAG and OpenAI's Responses API across benchmarks, particularly strong results on questions that require aggregation or exhaustive lists.
Key Highlights:
Aggregative query handling - S-RAG executes SQL queries over structured databases to answer questions requiring filtering, comparison, or aggregation across dozens of records. These operations can’t be performed by standard RAG because it passes a fixed number of text chunks to an LLM with limited capabilities.
Traceability - Every answer traces back to specific SQL queries and original source documents, giving you full auditability for compliance and regulatory workflows where you need to show exactly how the system reached its conclusion.
Hybrid retrieval - Maestro automatically routes queries between structured SQL operations and embedder-based retrieval depending on the question type.
Schema flexibility - AI21 Maestro automatically detects recurring patterns in your documents and generates schemas that standardize inconsistent formats ("1,000,000" vs "1M" vs "1"). You can also review and edit schemas before ingestion.
You can explore the full technical implementation in AI21's research paper. It is now available on Maestro for enterprises.
Quick Bites
OpenAI GPT 5.1 is out to all users in ChatGPT and API
OpenAI is upgrading its GPT-5 model series with GPT-5.1 Instant and Thinking. The team says the models score higher on factuality and complex problem-solving than GPT-5, and also have a more natural, conversational tone. Although no official benchmark performance has been released, early feedback from users is pouring in on genuine improvements in speed, creative writing quality, and code performance.
The release includes eight preset chat styles (professional, candid, quirky, friendly, efficient, nerdy, cynical, plus default) that you can now select directly in your personalization tab. Custom instructions also work more reliably now, actually sticking to your preferences across conversation turns instead of drifting.
Free guide to understand the Agent Protocol Landscape
If you’ve been trying to make sense of how agent protocols fit together, this guide lays it out without fluff: MCP links agents to tools and data, AG-UI connects agent backends with frontends, and Agent2Agent lets agents from different frameworks talk to each other. Worth a read if you want to ship smoother, more connected agents.
Meta’s open-source ASR models for languages never covered before
Meta has released the Omnilingual ASR, a suite of open-source speech recognition models covering over 1,600 languages, including 500 low-resource ones. The models and data are released under permissive open licences (Apache 2.0 for models, CC-BY 4.0 for the corpus). What stands out is that you can extend the system to new languages with only a few paired audio-text examples, rather than full training datasets. If you’re working in underrepresented linguistic regions, this is worth checking out for building transcription tools with models that achieve a character error rate under 10% for 78% of supported languages.
OpenAI’s free cookbook on self-improving AI agents
OpenAI published a cookbook on building agents that improve themselves through automated feedback loops. The system runs agent outputs through evaluators, uses a metaprompt to refine instructions when scores fall short, and automatically adopts better versions. While the showcase is on regulatory documentation in healthcare, this is broadly applicable to any domain demanding auditability and iteration. It’s a solid resource if you’re building agents that must adapt and scale.
AI PALs that can see, hear, act, and evolve
What if your AI assistant could video call you with a realistic face, pick up on your mood from your tone, and text you proactively when you've forgotten something? Tavus just released PALs, emotionally intelligent AI companions built on proprietary models that handle perception, real-time avatar rendering, and natural conversation flow. They plug into your calendar and email via MCP to manage tasks autonomously, and each PAL comes with a distinct personality that evolves as it learns your workflow and preferences. They're designed to feel less like tools and more like coworkers who remember your preferences and adapt over time, available through video calls, phone, or text. Honestly, this might be how we all interact with computers soon. You can apply for early access.
Fei-Fei Li’s World Labs releases 3D world model
AI Godmother Fei-Fei Li’s World Labs’ first product is out. They have released Marble, a multimodal world model that generates full 3D worlds from text, images, video, or even coarse 3D layouts, then lets you edit and expand them with fine-grained control before exporting as Gaussian splats, meshes, or enhanced videos. A standout feature is the "Chisel" tool - lay out basic 3D shapes to define structure, add a text prompt for style, and Marble fills in the details. It’s available to try for all.
Tools of the Trade
Data Formulator - Microsoft Research's open-source tool to analyze data from screenshots, Excel files, or databases and create visualizations. Either let AI agents explore from high-level goals or guide them step-by-step with prompts and interface controls. Runs locally or in-browser. Shows you the code, formulas, and reasoning behind every visualization it generates.
Davia - Open-source tool that generates interactive internal documentation for your local codebase. Point it at a project path and it writes documentation files locally with interactive visualizations that you can edit in a Notion-like platform or locally in your IDE.
qqqa - Fast, stateless LLM-powered assistant for your shell. It gives two binaries—
qqfor quick Q&A andqafor single-step agentic tasks (read/write files, execute commands with confirmation). Supports multiple LLM providers and can piggyback on existing ChatGPT or Claude subscriptionsAwesome LLM Apps - A curated collection of LLM apps with RAG, AI Agents, multi-agent teams, MCP, voice agents, and more. The apps use models from OpenAI, Anthropic, Google, and open-source models like DeepSeek, Qwen, and Llama that you can run locally on your computer.
(Now accepting GitHub sponsorships)

Hot Takes
Heard an SF founder once say: "Doesn't matter if model updates eat my product in 18 months, I'll collect enough in secondaries at Series A/B" 🥸
1. Investors will lose $ but tbh their 30x revenue multiples is enabling this.
2. 9-9-6 founding team gets the worst end of the stick, not enough equity for founder level liquidity, limited exit opps.
Exceptions- actual infra layer (opinion):
@exa, @cursor_ai @modal @togethercompute, Hex, @cerebras (few more)
~ Pooja NagpalYann LeCun is finally leaving Meta.
An outcome that is inevitable after Zuck spent $15B to acquire Alexandr Wang and made Yann report to him.
OpenAI’s LLMs and ChatGPT have made Zuck panic. Llama 4 flopped, and Yann never believed in LLM-to-AGI. Zuck’s patience ran out.
Years later, Zuck might buy Yann back at a crazy price, just like Google did with Noam.
That’s all for today! See you tomorrow with more such AI-filled content.
Don’t forget to share this newsletter on your social channels and tag Unwind AI to support us!
PS: We curate this AI newsletter every day for FREE, your support is what keeps us going. If you find value in what you read, share it with at least one, two (or 20) of your friends 😉
Reply